TTS Generation WebUI-用于AI音频生成的WebUI
TTS Generation WebUI-用于AI音频生成的WebUI
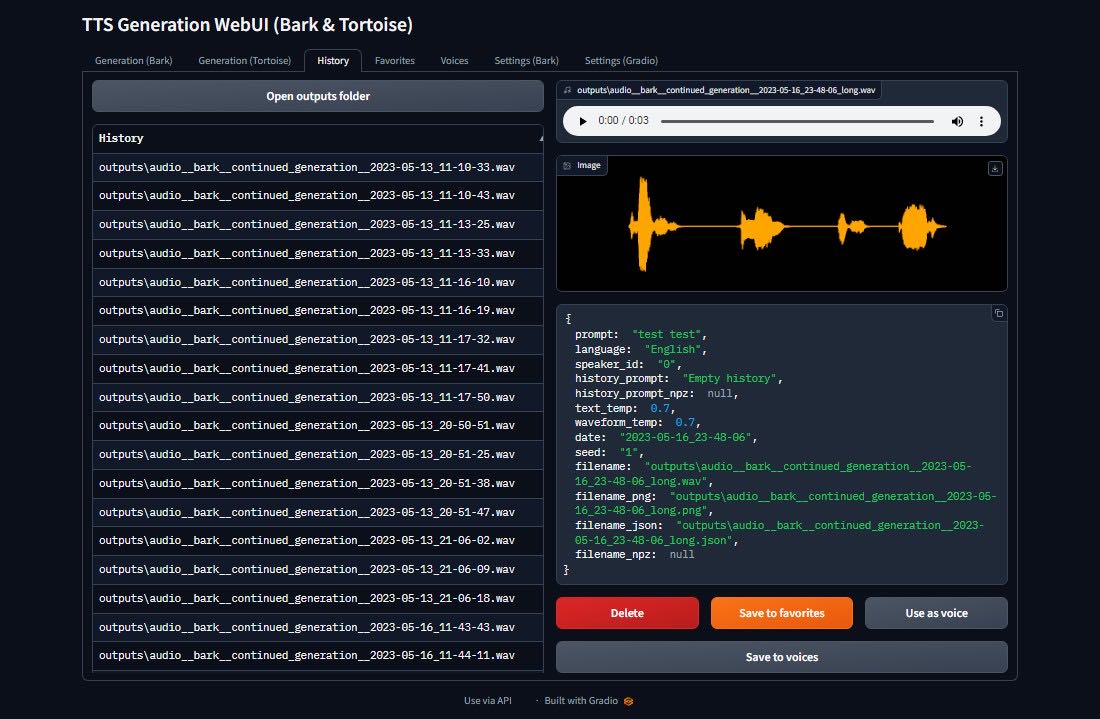
noiseTTS Generation WebUI 是一个免费的基于 gradio 的 Web 界面,用于文本转语音、音频和音乐生成,它同时支持手动安装及Docker 容器内运行。
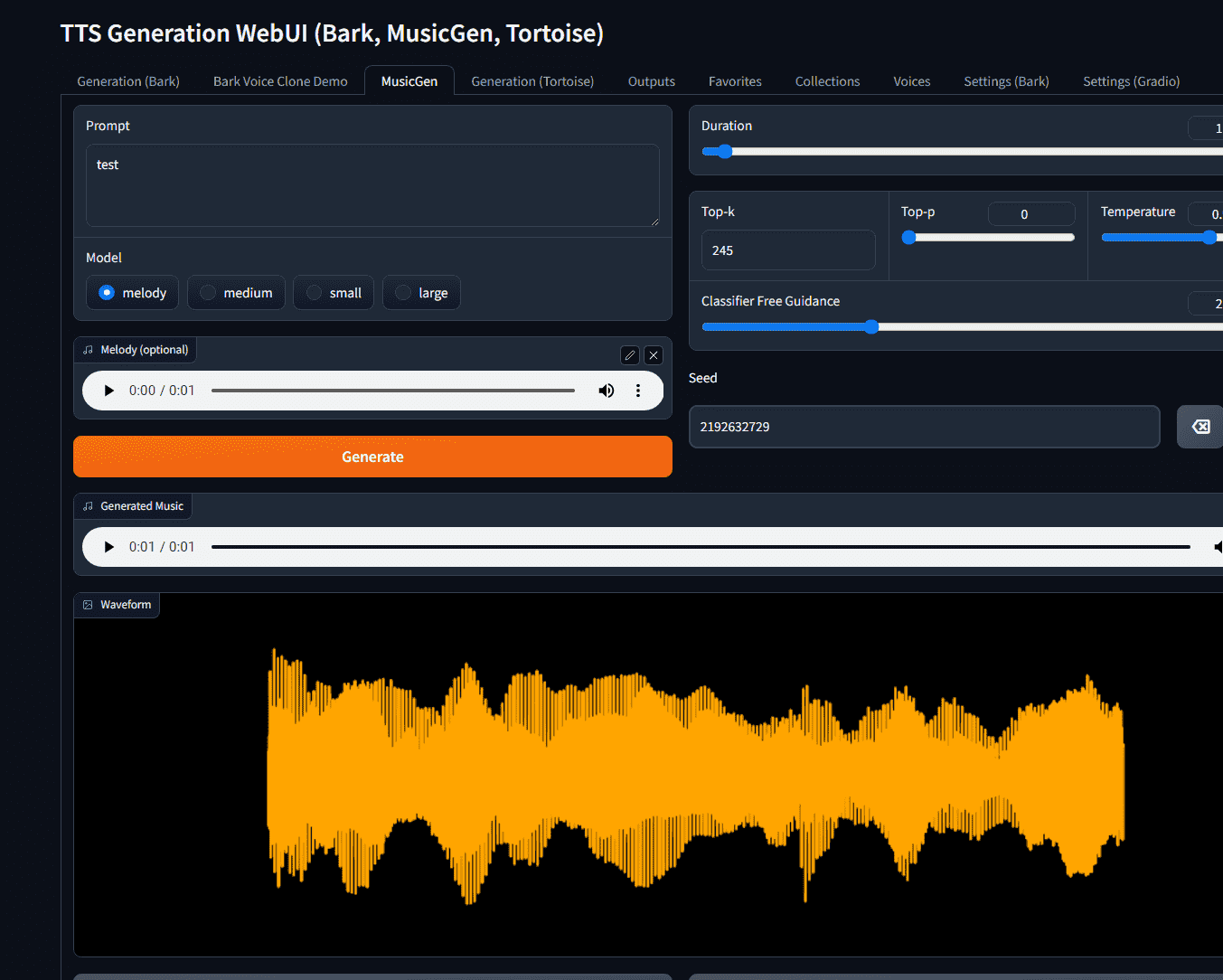
此 webui 允许您使用各种模型从文本生成音频,包括 Bark、MusicGen、Tortoise 和 RVC。
开源地址:https://github.com/rsxdalv/tts-generation-webui
下载:https://github.com/rsxdalv/one-click-installers-tts/archive/refs/tags/v6.0.zip
.png)
特征
轻松生成文本到语音
只需点击几下即可生成高质量的语音音频。
多功能 AI 模型
利用强大的 AI 模型(如 Bark、MusicGen、Tortoise 和 Vocos)执行不同的 TTS 任务。
广泛的语音选择
从 Bark Speaker Directory 访问各种声音和其他声音。
模型配置
| 论点 | 默认值 | 描述 |
|---|---|---|
text_use_gpu |
true |
确定是否应将 GPU 用于文本处理。 |
text_use_small |
true |
确定是否应使用文本模型的“小”版本或缩小版本。 |
coarse_use_gpu |
true |
确定是否应将 GPU 用于“粗略”处理。 |
coarse_use_small |
true |
确定是否应使用“粗略”模型的“小”或缩小版本。 |
fine_use_gpu |
true |
确定是否应将 GPU 用于“精细”处理。 |
fine_use_small |
true |
确定是否应使用“精细”模型的“小”或缩小版本。 |
codec_use_gpu |
true |
确定是否应使用 GPU 进行编解码器处理。 |
load_models_on_startup |
false |
确定是否应在应用程序启动期间加载模型。 |



喜欢这篇文章的人也看了




评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果