智能视频多语言AI配音/翻译工具 - Linly-Dubbing
智能视频多语言AI配音/翻译工具 - Linly-Dubbing
noise
介绍
Linly-Dubbing 是一个智能视频多语言AI配音和翻译工具,它融合了YouDub-webui的灵感,并在此基础上进行了拓展和优化。我们致力于提供更加多样化和高质量的配音选择,通过集成Linly-Talker的数字人对口型技术,为用户带来更加自然的多语言视频体验。
Github:https://github.com/Kedreamix/Linly-Dubbing
通过整合最新的AI技术,Linly-Dubbing 在多语言配音的自然性和准确性方面达到了新的高度,适用于国际教育、全球娱乐内容本地化等多种场景,帮助团队将优质内容传播到全球各地。
主要特点包括:
- 多语言支持: 支持中文及多种其他语言的配音和字幕翻译,满足国际化需求。
- AI 智能语音识别: 使用先进的AI技术进行语音识别,提供精确的语音到文本转换和说话者识别。
- 大型语言模型翻译: 结合领先的本地化大型语言模型(如GPT),快速且准确地进行翻译,确保专业性和自然性。
- AI 声音克隆: 利用尖端的声音克隆技术,生成与原视频配音高度相似的语音,保持情感和语调的连贯性。
- 数字人对口型技术: 通过对口型技术,使配音与视频画面高度契合,提升真实性和互动性。
- 灵活上传与翻译: 用户可以上传视频,自主选择翻译语言和标准,确保个性化和灵活性。
- 定期更新: 持续引入最新模型,保持配音和翻译的领先地位。
我们旨在为用户提供无缝、高质量的多语言视频配音和翻译服务,为内容创作者和企业在全球市场中提供有力支持。
TO DO LIST
- 完成AI配音和智能翻译功能的基础实现
- 集成CosyVoice的AI声音克隆算法,实现高质量音频翻译
- 增加FunASR的AI语音识别算法,特别优化对中文的支持
- 利用Qwen大语言模型实现多语言翻译
- 开发Linly-Dubbing WebUI,提供一键生成最终视频的便捷功能,并支持多种参数配置
- 加入UVR5进行人声/伴奏分离和混响移除,参考GPTSoVits
- 提升声音克隆的自然度,考虑使用GPTSoVits进行微调,加入GPTSoVits
- 实现并优化数字人对口型技术,提升配音与画面的契合度
演示
| 原视频 | Linly-Dubbing |
|---|---|
安装与使用指南
测试环境
本指南适用于以下测试环境:
- Python 3.10, PyTorch 2.3.1, CUDA 12.1
- Python 3.10, PyTorch 2.3.1, CUDA 11.8
请按照以下步骤进行Linly-Dubbing的安装与配置。
1. 克隆代码仓库
首先,您需要将Linly-Dubbing项目的代码克隆到本地,并初始化子模块。以下是具体操作步骤:
1 | # 克隆项目代码到本地 |
2. 安装依赖环境
在继续之前,请创建一个新的Python环境,并安装所需的依赖项。
1 | # 创建名为 'linly_dubbing' 的conda环境,并指定Python版本为3.10 |
根据您的CUDA版本,使用以下命令安装PyTorch及相关库:
1 | # 对于CUDA 11.8 |
如果您倾向于通过conda安装PyTorch,可以选择以下命令:
1 | # 对于CUDA 11.8 |
然后,安装项目的其他依赖项:
1 | # 安装项目所需的Python包 |
如在安装过程中遇到错误提示“Could not load library libcudnn_ops_infer.so.8”,请按以下步骤修复:
1 | # 设置LD_LIBRARY_PATH以包含正确的cuDNN库路径 |
3. 配置环境变量
在运行程序前,您需要配置必要的环境变量。请在项目根目录下的 .env 文件中添加以下内容,首先将 env.example填入以下环境变量并 改名为 .env :
OPENAI_API_KEY: 您的OpenAI API密钥,格式通常为sk-xxx。MODEL_NAME: 使用的模型名称,如gpt-4或gpt-3.5-turbo。OPENAI_API_BASE: 如使用自部署的OpenAI模型,请填写对应的API基础URL。HF_TOKEN: Hugging Face的API Token,用于访问和下载模型。HF_ENDPOINT: 当遇到模型下载问题时,可指定自定义的Hugging Face端点。APPID和ACCESS_TOKEN: 用于火山引擎TTS的凭据。
通常,您只需配置 MODEL_NAME 和 HF_TOKEN 即可。
默认情况下,MODEL_NAME 设为 Qwen/Qwen1.5-4B-Chat,因此无需额外配置 OPENAI_API_KEY。
您可以在 Hugging Face 获取 HF_TOKEN。若需使用说话人分离功能,务必在pyannote/speaker-diarization-3.1申请访问权限。否则,可以选择不启用该功能。
4. 运行程序
在启动程序前,先通过以下命令自动下载所需的模型(包括Qwen,XTTSv2,CosyVoice模型,Qwen模型和faster-whisper-large-v3模型):
1 | bash scripts/download.sh |

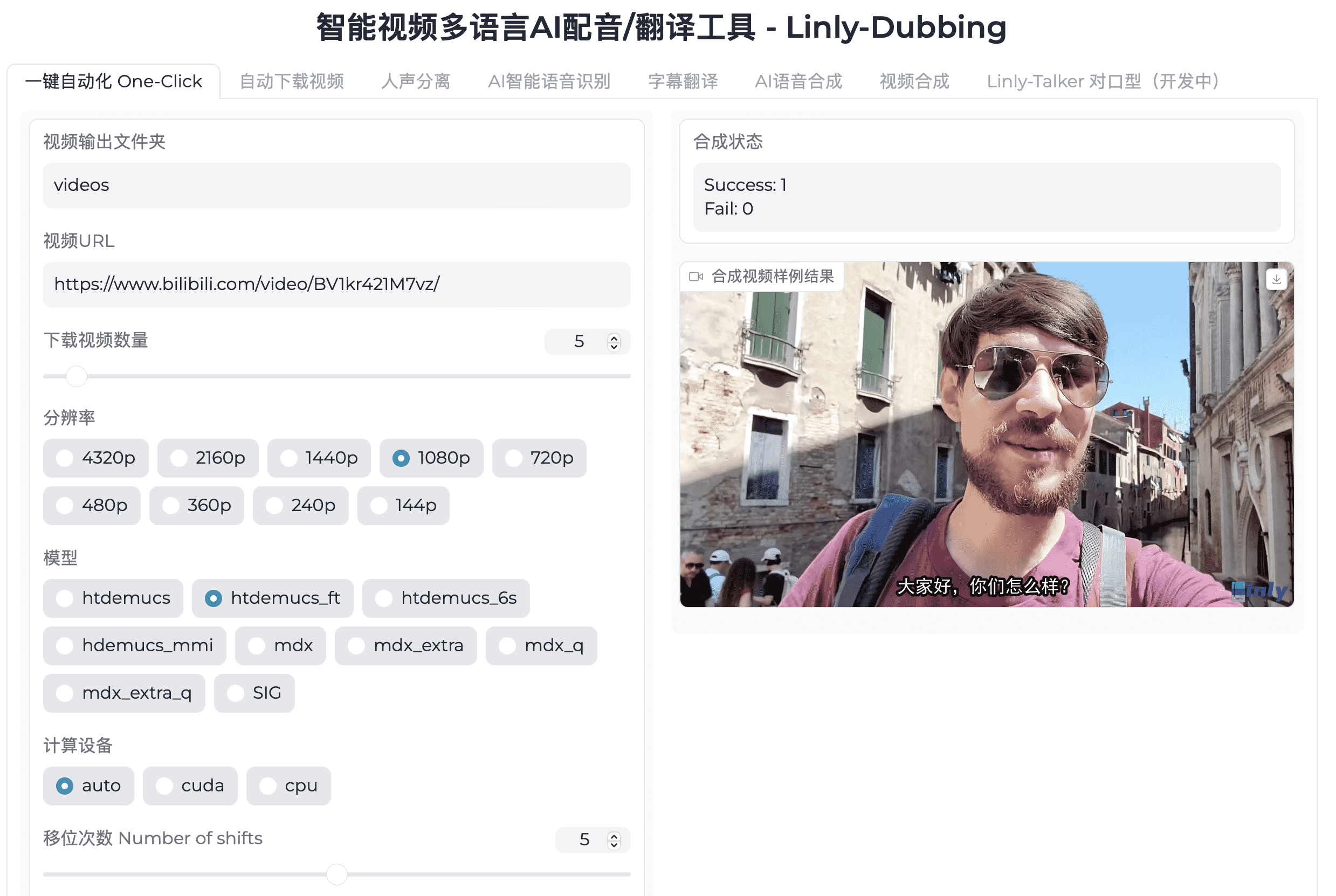
下载完成后,使用以下命令启动WebUI用户界面:
1 | python webui.py |
启动后,您将看到如下图所示的界面: